NewRelicを使ってWordPressを監視
Standard
From Telegraf To NewRelic
Standard…
nri-bundle-newrelic-pixie CreateContainerConfigError
Standard…
DevSecOps Learning
Standard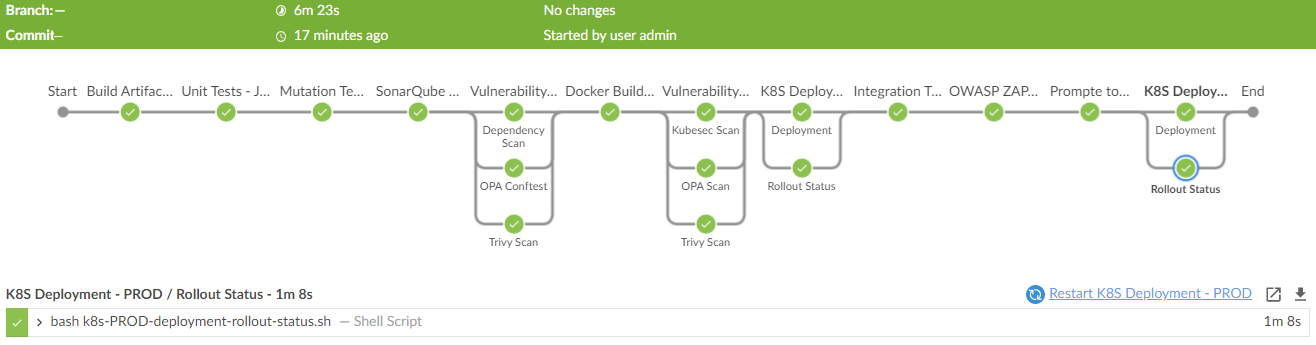
本以为是招DevOps,结果是DevSecOps,这回多了一块Sec方面要学。
DevOpsを応募していたつもりが、DevSecOpsになって、今回はこのSecについてのものを学ぶ必要があると思います。
说实话,对这工作还是比较有兴趣的。
正直なところ、この仕事は楽しいです。
为了能更快适应工作,平时晚上和双休几乎都在看资料文档,并且不停地在自己环境下试手。
より早く仕事に適応するために、休みにはほぼドキュメントを読んだり、自分の環境で試してみたりしています。
总算试着把DevSecOps所涉及的一些东西跑通。
ようやく自動的に構築、テスト、脆弱性検出、デプロイをJenkins Piplineで実行できました。
頑張ります!
NodejsでIPOリストを取得
Standard
2e214c35490dd154465fde962d2030b1007
LaravelでGoutteを利用してWebスクレイピング
Standardcurl -s https://laravel.build/my_scraping | bash cd my_scraping/ vim my.cnf [mysqld] character-set-server = utf8mb4 collation-server = utf8mb4_general_ci [client] default-character-set=utf8mb4 vim docker-compose.yml # ... volumes: - 'sailmysql:/var/lib/mysql' - ./my.cnf:/etc/mysql/conf.d/my.cnf ./vendor/bin/sail up -d --build docker ps CONTAINER ID IMAGE COMMAND PORTS ... 67309004de4b sail-8.0/app "start-container" 0.0.0.0:80->80/tcp, 8000/tcp ... aabaeb2f98dc selenium/standalone-chrome "/opt/bin/entry_poin…" 4444/tcp ... 17e6f413e14b getmeili/meilisearch:latest "tini -- /bin/sh -c …" 0.0.0.0:7700->7700/tcp ... 06eef68262bc mailhog/mailhog:latest "MailHog" 0.0.0.0:1025->1025/tcp, 0.0.0.0:8025->8025/tcp ... 63dfe21f304a redis:alpine "docker-entrypoint.s…" 0.0.0.0:6379->6379/tcp ... cfbf2e6c3ee4 mysql:8.0 "docker-entrypoint.s…" 0.0.0.0:3306->3306/tcp, 33060/tcp ... ### ./vendor/bin/sail composer require weidner/goutte vim config/app.php return [ // ... 'providers' => [ // ... Weidner\Goutte\GoutteServiceProvider::class, ], // ... 'aliases' => [ // ... 'Goutte' => Weidner\Goutte\GoutteFacade::class, ], ]; ./vendor/bin/sail php artisan make:command ScrapeMy vim app/Console/Commands/ScrapeMy.php // ... protected $signature = 'scrape:my'; protected $description = 'Scrape My'; // ... public function handle() { $crawler = \Goutte::request('GET', 'https://yemaosheng.com/'); $crawler->filter('article > header > h1')->each(function ($node) { dump($node->text()); }); } // ... ./vendor/bin/sail artisan list scrape scrape:my Scrape My ./vendor/bin/sail artisan scrape:my "今日は永住権を取得しました" "小鳥の保温について" ... # php artisan make:model MyUrls --migration Model created successfully. Created Migration: 2021_07_02_053959_create_my_urls_table vim database/migrations/2021_07_02_053959_create_my_urls_table.php // ... public function up() { Schema::create('my_urls', function (Blueprint $table) { $table->id(); $table->string('url'); $table->timestamps(); }); } // ... ./vendor/bin/sail artisan migrate ### vim app/Console/Commands/ScrapeMy.php // ... use Carbon\Carbon; use Illuminate\Support\Facades\DB; // ... public function handle() { $this->truncateTables(); $this->saveUrls(); } private function truncateTables(){ DB::table('my_urls')->truncate(); } private function saveUrls(){ $url = 'https://tenshoku.my.jp/list/kwphp/pg2/'; $crawler = \Goutte::request('GET', $url); $urls = $crawler->filter('.cassetteRecruit__copy > a')->each (function ($node) { $href = $node->attr('href'); return [ 'url' => substr($href, 0, strpos($href,'/', 1)+1), 'created_at' => Carbon::now(), 'updated_at' => Carbon::now(), ]; }); DB::table('my_urls')->insert($urls); } ./vendor/bin/sail artisan scrape:my ### ./vendor/bin/sail artisan make:model MyJobs --migration Model created successfully. Created Migration: 2021_07_02_060002_create_my_jobs_table vim database/migrations/2021_07_02_060002_create_my_jobs_table.php // ... public function up() { Schema::create('my_jobs', function (Blueprint $table) { $table->id(); $table->string('url'); $table->string('title'); $table->string('company_name'); $table->text('features'); $table->timestamps(); }); } // ... ./vendor/bin/sail artisan migrate Migrating: 2021_07_02_060002_create_my_jobs_table Migrated: 2021_07_02_060002_create_my_jobs_table (52.56ms) vim app/Console/Commands/ScrapeMy.php <?php namespace App\Console\Commands; use App\Models\MynaviUrls; use App\Models\MynaviJobs; use Illuminate\Console\Command; use Carbon\Carbon; use Illuminate\Support\Facades\DB; class ScrapeMynavi extends Command { const HOST = 'https://tenshoku.mynavi.jp'; const FILE_PATH = 'app/mynavi_jobs.csv'; const PAGE_NUM = 1; protected $signature = 'scrape:mynavi'; protected $description = 'Scrape Mynavi'; public function __construct() { parent::__construct(); } public function handle() { $this->truncateTables(); $this->saveUrls(); $this->saveJobs(); $this->exportCSV(); } private function truncateTables(){ DB::table('mynavi_urls')->truncate(); DB::table('mynavi_jobs')->truncate(); } private function saveUrls(){ foreach(range(1,$this::PAGE_NUM) as $num) { $url = $this::HOST.'/list/kwphp/pg' . $num . '/'; $crawler = \Goutte::request('GET', $url); $urls = $crawler->filter('.cassetteRecruit__copy > a')->each (function ($node) { $href = $node->attr('href'); return [ 'url' => substr($href, 0, strpos($href,'/', 1)+1), 'created_at' => Carbon::now(), 'updated_at' => Carbon::now(), ]; }); DB::table('mynavi_urls')->insert($urls); //sleep(5); } } private function saveJobs(){ foreach(MynaviUrls::all() as $mynaviUrl){ $url = $this::HOST.$mynaviUrl->url; $crawler = \Goutte::request('GET', $url); MynaviJobs::create([ 'url' => $url, 'title'=> $this->getTitle($crawler), 'company_name' => $this->getCompany($crawler), 'features' => $this->getFeatures($crawler), 'created_at' => Carbon::now(), 'updated_at' => Carbon::now(), ]); sleep(1); } } private function getTitle($crawler){ return $crawler->filter('.occName')->text(); } private function getCompany($crawler){ return $crawler->filter('.companyName')->text(); } private function getFeatures($crawler){ $features = $crawler->filter('.cassetteRecruit__attribute > li > span')->each(function($node){ return $node->text(); }); return implode(' && ', $features); } private function exportCSV(){ $file = fopen(storage_path($this::FILE_PATH), 'w'); if(!$file){ throw new \Exception('ファイルを作成に失敗しました!'); } if(!fputcsv($file,['id','url','title','company_name','features'])){ throw new \Exception('ヘッダの書き込みに失敗しました!'); } foreach(MynaviJobs::all() as $job){ if(!fputcsv($file,[$job->id,$job->url,$job->title,$job->company_name,$job->features])){ throw new \Exception('CSVファイルの書き込みに失敗しました!'); } } fclose($file); } } |
run bookinfo with microk8s istio
Standardmicrok8s enable istio snap alias microk8s.kubectl mk mk create namespace bookinfo mk label namespace bookinfo istio-injection=enabled mk config set-context --current --namespace=bookinfo mk apply -f https://raw.githubusercontent.com/istio/istio/release-1.12/samples/bookinfo/platform/kube/bookinfo.yaml mk apply -f https://raw.githubusercontent.com/istio/istio/release-1.12/samples/bookinfo/networking/bookinfo-gateway.yaml mk apply -f https://raw.githubusercontent.com/istio/istio/release-1.12/samples/bookinfo/networking/destination-rule-all-mtls.yaml mk apply -f https://raw.githubusercontent.com/istio/istio/release-1.12/samples/bookinfo/networking/virtual-service-all-v1.yaml mk get virtualservices NAME GATEWAYS HOSTS AGE bookinfo ["bookinfo-gateway"] ["*"] 15m mk get gateway NAME AGE bookinfo-gateway 15m mk get pod -l app=ratings --show-labels NAME ... LABELS ratings-v1-xxx ... app=ratings,... mk exec "$(mk get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}')" -c ratings -- curl -sS productpage:9080/productpage | grep -o "<title>.*</title>" <title>Simple Bookstore App</title> |
my shell configuration
Standardsh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k git clone https://github.com/pyenv/pyenv.git ~/.pyenv echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zprofile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zprofile echo 'eval "$(pyenv init --path)"' >> ~/.zprofile echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.profile echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.profile echo 'eval "$(pyenv init --path)"' >> ~/.profile echo 'eval "$(pyenv init -)"' >> ~/.zshrc sed 's/\(^plugins=([^)]*\)/\1 zsh-autosuggestions zsh-syntax-highlighting pyenv z microk8s/' ~/.zshrc grep -v -e ^# -e ^$ ~/.zshrc if [[ -r "${XDG_CACHE_HOME:-$HOME/.cache}/p10k-instant-prompt-${(%):-%n}.zsh" ]]; then source "${XDG_CACHE_HOME:-$HOME/.cache}/p10k-instant-prompt-${(%):-%n}.zsh" fi export ZSH="/home/ye/.oh-my-zsh" ZSH_THEME="powerlevel10k/powerlevel10k" plugins=(git zsh-autosuggestions zsh-syntax-highlighting pyenv z microk8s) source $ZSH/oh-my-zsh.sh alias kubectl="microk8s.kubectl" [[ ! -f ~/.p10k.zsh ]] || source ~/.p10k.zsh eval "$(pyenv init -)" |
2021春節おめでとう
Standard